Injecting Language into the 3D World - Part II
Published:
Part II moves from spatial reasoning to embodied intelligence. We examine how large language models conditioned on 3D scene representations transition from passive understanding to active decision-making. The discussion focuses on 3D task planning, navigation, object manipulation, and safety constraints.
Table of Contents
- 1. Introduction to 3D Embodiment
- 2. 3D Task Planning
- 3. 3D Navigation
- 4. 3D Object Manipulation
- 5. Safety and Reliability
- Key Takeaways
- References
1. Introduction to 3D Embodiment
In Part I of this series, we explored how injecting structured 3D representations into large language models enables spatial reasoning beyond static 3D perception, bringing these models closer to human-level understanding of interaction and spatial relationships.
Embodied intelligence can be viewed as the natural next step in this progression. It requires not only understanding the 3D world, but also acting within it. This includes generating task plans, navigating through space, and manipulating objects while respecting spatial context and physical constraints. In this sense, the transition toward embodiment introduces a fundamental shift:
\[\text{Understanding Space} \rightarrow \text{Acting Within Space}\]Although 3D-LLMs can produce grounded responses about spatial relationships, they do not model world dynamics, generate control signals, or validate actions under physical constraints. Their reasoning remains at the language level.
In this section, we examine how current 3D-LLM approaches extend toward embodied intelligence across three core robotic tasks Planning, Navigation, and Manipulation, and discuss the safety implications of deploying such systems in real-world environments.
We analyze LEO’s design and training strategy in depth, highlighting how it integrates the three embodied tasks and comparing its contributions to prior 3D-LLM for the same research direction.
2. 3D Task Planning
The planning task is essential for navigating and manipulating within the environment, and the accuracy of the plan directly impacts the success of downstream tasks.
Given a 3D scene representation \(\mathcal{S}\) and a high-level goal \(g\), the model predicts a sequence of actions that could achieve the goal:
\[\{a_1, a_2, \dots, a_T\} \sim P(a_t \mid a_{<t}, \mathcal{S}, g)\]Many prior works have tackled this problem from a 2D vision-language-action (VLA) perspective, often neglecting the broader dynamics of the 3D physical world and the relationship between actions and future states. In contrast, 3D-VLA introduces a 3D generative world model that links 3D perception, reasoning, and action within a unified framework. The authors argue that humans rely on imagining future scenarios over a temporal horizon and plan actions accordingly, while reasoning about their consequences.
I personally find this argument intuitive and worthy of further exploration, and the authors introduce different types of building blocks as planning components to support this idea.
The model is built on top of a 3D-LLM architecture, while using BLIP2-FlanT5XL as the pretrained backbone (including its Q-Former). Separately, the pretrained diffusion decoders are aligned to the LLM embedding space via a transformer-based projector.
To enable embodied interaction, 3D-VLA extends the token vocabulary with structured interaction tokens for a 7-DoF robotic arm:
<obj></obj>to explicitly mark manipulated objects.<loc0-255>tokens to represent discretized 3D bounding boxes.<scene></scene>to enclose 3D scene embeddings.- Action tokens
<aloc0-255>,<arot0-255>, and<gripper0/1>to represent state parameters. <ACT SEP>to separate consecutive actions.
Goal Imagination via Diffusion Models (DM)
To support planning, 3D-VLA first generates an imagined goal state (RGB-D or point cloud), which provides structured future context for subsequent action prediction, as shown in the figure below, upper left.
For RGB-D generation, the DM is based on Stable Diffusion v1.4, with RGB and depth latents concatenated as input. For point cloud generation, it builds upon Point-E, adding point cloud conditioning.
After pretraining, the diffusion decoders are aligned with the LLM embedding space through a projector. Additional special tokens such as <image> and <pcd> are introduced to specify the modality to be generated.
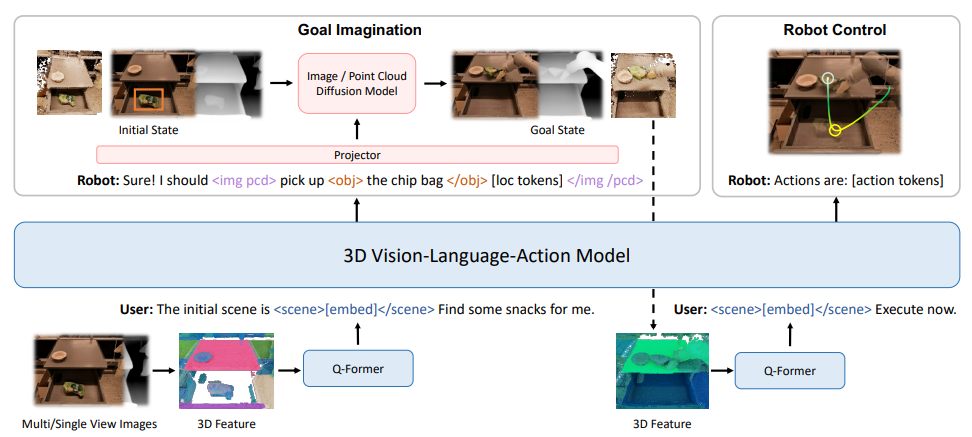
Figure: 3D-VLA architecture.
The LLM produces structured outputs between these tokens, and the projector maps LLM embeddings into the diffusion model space. LoRA is used to fine-tune the diffusion models, while only the newly introduced token embeddings, the output linear layer, and the projector are trained.
The objective minimizes both the LLM loss for action prediction and the diffusion denoising loss for goal generation:
\[\mathcal{L} = \mathcal{L}_{LLM} + \lambda \mathcal{L}_{DM}\]3D Embodied Instruction Dataset
Without 3D information, robots struggle to locate objects and estimate distances, orientations, and spatial relationships. Therefore, training the generative model requires a dataset containing 3D scene representations paired with language instructions and action annotations.
The authors curate a large-scale dataset from robotics and human-object interaction sources and enrich it with depth maps using ZoeDepth, lifted 3D point clouds, 3D bounding boxes via Grounded-SAM, structured textual descriptions, and action annotations.
They also use predefined language templates with tokens to construct prompts and answers, and further diversify them using ChatGPT-based prompting with few-shot human demonstrations.
We observe that 3D-VLA, evaluated on RLBench and CALVIN, outperforms prior baselines and 2D-based VLA methods, even in open-loop settings, due to its integration of 3D representations, object localization, and goal imagination for more informed action prediction.
Planning is essential for navigation and manipulation, as it provides a high-level roadmap for decision-making. We discuss the modeling of actions for two downstream tasks in the following sections.
3. 3D Navigation
Navigation requires reasoning about the agent’s position in the map, the environment topology, and movements toward a goal. Classical navigation systems rely on occupancy maps and planning algorithms, and can be extended with reinforcement learning policies.
We explore NaviLLM, which models embodied navigation through schema-based instruction following, enabling a wide range of navigation capabilities rather than learning task-specific policies as in the case of 3D-VLA.
In embodied navigation, an agent situated in a 3D environment must complete tasks described in natural language. The agent leverages past trajectories and current observations to predict actions, which may include navigation moves, object selections, bounding boxes, or textual responses.
NaviLLM comprises two main modules: a Scene Encoder and a Schema-Based Instructions. The scene encoder processes multi-view visual observations using a pre-trained Vision Transformer (ViT) to extract per view features, which are then fused through a Transformer encoder to model spatial relationships across viewpoints. GPS coordinates and orientation angles are incorporated as additional tokens to enrich the spatial encoding.
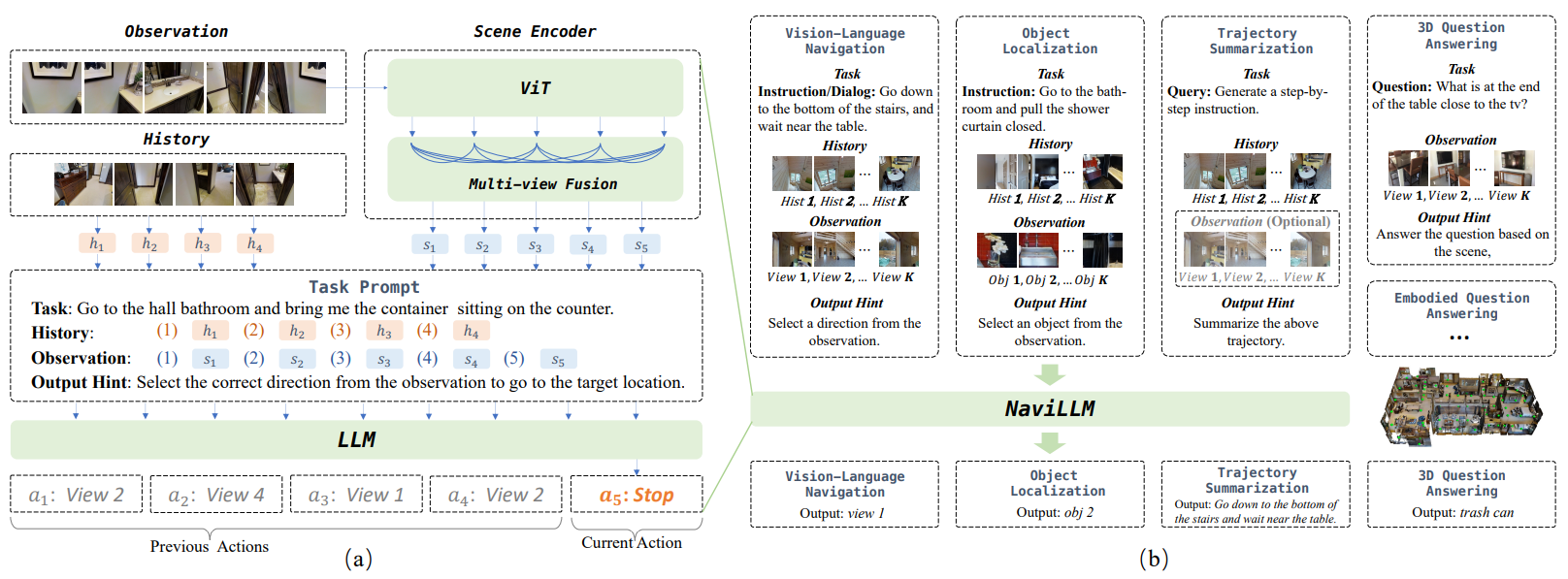
Figure: NaviLLM architecture.
The core contribution is the Schema-Based Instructions, which unify navigation and related embodied tasks into structured problem. Each navigation instance is introduced using four components as shown in the figure above:
- Task: a natural language instruction describing the objective (e.g., navigate to a location, search for an object, or answer a question).
- Observation: the current scene representations from all reachable viewpoints.
- History: past observations that provide temporal context about previous decisions and trajectories.
- Output Hint: guidance for the expected output format, such as selecting the next viewpoint to move toward or generating a textual response.
As the agent moves, the history is updated accordingly to maintain temporal consistency.
The model fine tunes a multi-view fusion Transformer and an LLM built on Vicuna-7B, while keeping the ViT backbone frozen under a cross-entropy loss for action prediction.
NaviLLM demonstrates strong performance across multiple embodied navigation benchmarks and shows promising generalization to unseen tasks through its unified schema-based design
4. 3D Object Manipulation
Object manipulation refers to the ability of an agent to physically interact with objects in the environment, such as picking, placing, opening, closing, or using tools. Compared to navigation, manipulation requires reasoning about object affordances, modeling contact dynamics during interaction, and ensuring the stability of grasps.
Following the tokenization introduced in 3D-VLA, LEO represents robot movements through discrete action tokens. Built on top of the CLIPort framework, LEO discretizes action poses into 516 tokens: 320 tokens for x-axis position bins, 160 tokens for y-axis bins, and 36 tokens for z-axis rotation. This structured discretization enables the model to autoregressively generate precise manipulation commands conditioned on language instructions and the 3D scene context.
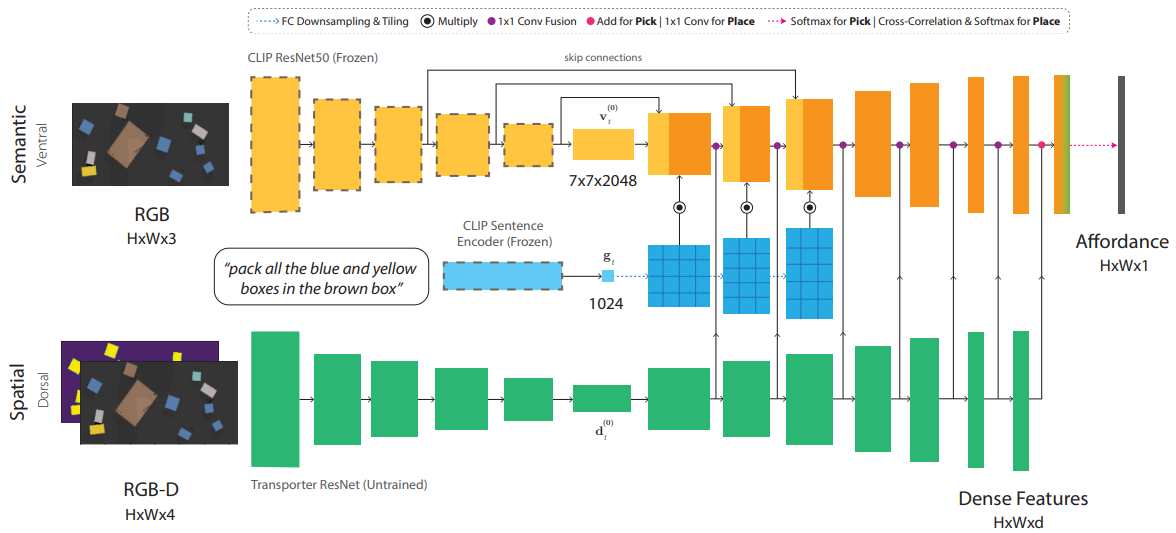
Figure: LEO architecture (CLIPort framework).
This limitation in affordance modeling motivates ManipLLM, which explicitly distinguishes between suitable and unsuitable regions for manipulation.
ManipLLM is built on LLaMA-Adapter, a Multimodal Large Language Model that combines a pretrained CLIP visual encoder with a LLaMA-7B model. Visual and text features are aligned through a multi-modal projection module. Instead of full fine-tuning, ManipLLM injects lightweight learnable adapters into both the visual encoder and the LLM, and only these adapters and the projection module are updated during training.
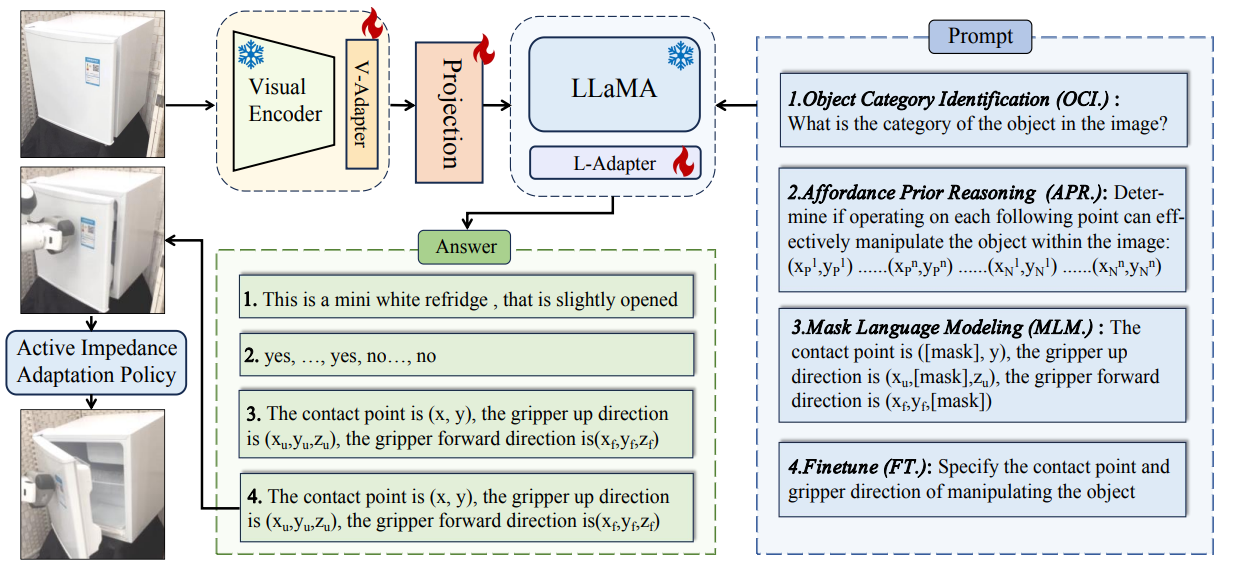
Figure: ManipLLM architecture.
The training paradigm is structured into three stages:
Object Category Identification.
The model recognizes the object category and provides category level priors, since objects within the same category share similar geometric and functional properties.
Affordance Prior Reasoning.
The model learns which image regions are manipulable by reasoning over affordance supervision. The affordance information is translated into language tokens to learn region-level actionability awareness.
Pose Prediction.
Finally, the model predicts the end-effector pose, including the contact pixel \((x, y)\) and the gripper orientation in discrete action space.
All stages are jointly optimized under a unified objective:
\[L = L_A + L_M + L_F\]where:
- \(L_A\) supervises affordance prior reasoning,
- \(L_M\) corresponds to masked language modeling for pose completion,
- \(L_F\) supervises pose prediction.
Given an RGB image and a text prompt, it sequentially reasons about the object category, identifies actionable regions, and outputs a contact point and gripper direction. The predicted pixel is projected into 3D space using depth information to establish the initial interaction.
Active Impedance Adaptation Policy
After initial contact, ManipLLM applies an active impedance adaptation policy, a closed loop control strategy that refines the predicted motion direction using force feedback (perturb and observe). Given an initial forward direction \(d_i\), small perturbations \(\zeta_j\) are introduced as \(d_{ij} = d_i + \zeta_j\), for each candidate direction \(d_{ij}\), a small force is applied and we measure the end effector movement \(\delta_j\). The optimal direction is selected with the largest movement formaly defined \(d_{\text{opt}} = \arg\max_j \|\delta_j\|\).
Compared to purely token-based systems such as LEO and 3D-VLA, ManipLLM integrates affordance reasoning, interpretable decision making, and adaptive physical control, moving manipulation beyond discrete action generation.
5. Safety and Reliability
As 3D-LLMs begin to generate executable plans and manipulation commands, safety becomes a central concern. Unlike text/chat errors, mistakes in physical actions can cause real harm. LLMs may hallucinate actions, misinterpret spatial context alongside the visual encoder, or lack understanding of control signals such as force, speed, and contact dynamics.
In my view, one major gap in current research is task-level safety benchmarking for 3D embodied agents and the development of metrics to assess hazardous behaviors, failure recovery, and related risks. Without safety benchmarks and a proper validation protocol, deploying 3D-LLM-based agents in real-world environments remains risky.
This could be addressed through simulation environments that place robots in challenging scenarios with potential hazards, pushing them beyond their comfort zone and evaluating the agent’s ability to recognize and avoid risks, recover from failures, ensure human safety, test new models, gather feedback, and iterate on design improvements before obtaining a certificate of safety compliance prior to deployment.
Yes, robots need a working permit as well, not only me 😂.
Key Takeaways
Embodied 3D-LLMs extend spatial reasoning to action generation, operating as high-level planners that decompose tasks into executable sequences conditioned on 3D scene representations.
Current systems reason at the language level rather than the control level. They lack explicit modeling of world dynamics, uncertainty propagation, and physical constraints, limiting their reliability in real-world deployment.
The central open problem is bridging the gap between discrete token-based reasoning and continuous control signals, requiring tighter integration of perception, planning, and low-level execution.
Building on this hot topic, we should explore injecting systems dynamics and control signals into the 3D-LLM architecture, physically informed modeling can help bridging the gap between LLM reasoning and system internal states, and enable more simulation-based training, as 3D-VLA does with goal imagination.
Summary of Embodied 3D-LLM Approaches
| Method | Year | Geometry | Vision Model | LLM Base | Alignment Module | Training (3D / LLM) |
|---|---|---|---|---|---|---|
| 3D-VLA | 2024 | Multi-View + Point Cloud | SAM / Mask2Former | Flan-T5 | Q-Former | LoRA for LLM DM alignment |
| NaviLLM | 2024 | Multi-View (GPS/Pose) | EVA-CLIP-Large | Vicuna-7B | Transformer | Freezing vision /Layer freezing LLM |
| ManipLLM | 2023 | RGB-D | CLIP | LLaMA-7B | Linear Projection + Adapters | Frozen vision / Adapter tuning LLM |
| LEO | 2023 | Point Cloud + Multi-View | OpenClip | Vicuna | Transformer | Frozen vision / LoRA tuning LLM |
References
- Zhen et al., 2024: 3D-VLA: A 3D Vision-Language-Action Generative World Model.
- Zheng et al., 2023: Towards Learning a Generalist Model for Embodied Navigation.
- Li et al., 2023: ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation.
- Huang et al., 2023: An Embodied Generalist Agent in 3D World.
- Shridhar et al., 2021: CLIPort: What and Where Pathways for Robotic Manipulation.
- Ma et al., 2024: When LLMs Step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models.
- Awesome-LLM-3D: Curated list of 3D + LLM papers and related foundation models.