Injecting Language into the 3D World - Part I
Published:
This article presents a structured and research-oriented exploration of how language models are integrated with 3D scene representations. We analyze alignment strategies, architectural design patterns, and task formulations including captioning, grounding, conversation, embodied decision-making, and text-to-3D generation.
Table of Contents
- 1. Introduction
- 2. The 3D-LLM Landscape and Alignment Strategies
- 4. LLMs as an Enhancer
- 5. LLMs for Multi-Tasking
- References
1. Introduction
Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated a remarkable ability in understanding and generating and reasoning over text and images. However, the 3D world is fundamentally different, unlike 2D images, 3D scenes are continuous and spatially structured. They encode rich geometry, layout, occlusion, and physical relationships that are not easily fed into LLMs as discrete tokens.
The core challenge is How do we inject a continuous geometric space into discrete token-based reasoning systems without losing the spatial fidelity?
This question was commonly asked by recent works in the 3D-LLM landscape, and raises some fundamental question:
How to represent 3D geometry in a structured and semantically rich way?
How to compress the spatial information into a fixed number of tokens that can be processed by LLMs? while achieving a fast and scalable inference?
How to preserve the strong reasoning capabilities of LLMs through the proposed alignment strategy?
Although 3D perception systems have achieved a high level performance in geometric reconstruction, they remain limited in interactive reasoning and instruction following, and even open-vocabulary generalization. LLMs, on the other hand have excelled in this context learning, chain of thought reasoning and instruction following. Bringing these two powerful paradigms together is a key step to move from static 3D scenes understanding towards interactive and spatially intelligent 3D systems.
In this blog, we explore how recent works bridged this gap, We analyze the architectural design, alignment strategies, and task formulations. Building on top of the survey “When LLMs Step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models”, we go deeper into representative papers and examine the design trade-offs that define the 3D-LLM landscape.
While writing this blog, I realized that the 3D-LLM landscape is vast and heavily related to concepts and foundations in LLMs, VLMs/VFMs, and Embodied AI, which will not be covered in depth here. This will be motivation for future blogs that dive deeper into these topics and structure our knowledge in a more modular way.
2. The 3D-LLM Landscape and Alignment Strategies
Two-Stage Pipeline and Alignment Modules
Current 3D-LLM pipelines can be conceptually decomposed into two main stages:
Stage 1 - 3D Feature Extraction: Transforming raw 3D data into structured representations that capture geometry, semantics, and spatial relationships. Common representations include point clouds, voxel grids, meshes, scene graphs, neural implicit representations (e.g., NeRF), 3D Gaussian splatting, and multi-view renderings.
Stage 2 - Alignment and Tokenization: Bridging continuous 3D features into 3D tokens or embeddings that can be processed by LLMs, enabling cross-modal reasoning and interaction.
This two-stage workflow reflects a common architectural design pattern that has emerged in recent works and surveys. The alignment modules used to connect 3D representations with LLMs are illustrated in the figure below:
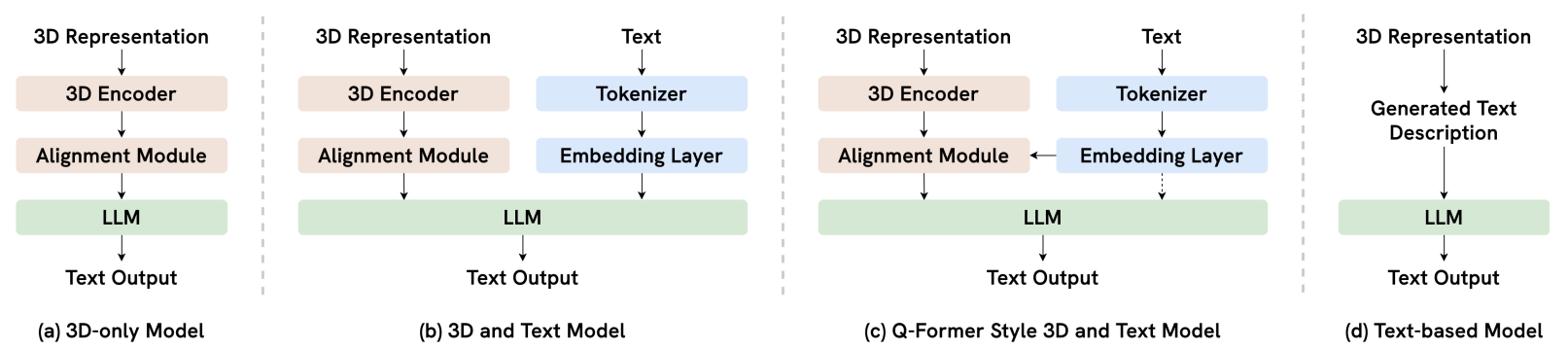
Figure: Alignment module design patterns.
3D-Only Model: Accepts 3D features as input and processes them through a linear or MLP layer to project them into the LLM embedding space.
3D and Text Model: Accepts both 3D features and text as input and processes them through two parallel branches to align the modalities, typically using Transformer-based architectures.
Q-Former Style 3D and Text Model: Introduces a set of learnable query tokens that attend to 3D features, with text conditioning the alignment process. This design is inspired by the Q-Former architecture in BLIP-2.
Text-Based Model: Converts the 3D scene into a textual representation—using bounding boxes, positions, relationships, and captions—allowing the LLM to process it directly, No Training is required.
The alignment modules are typically trained using cross entropy loss between the LLM generated captions and the ground truth captions, while freezing the 3D feature extractor and the LLM. We study the training and evaluation strategies in more depth in the 3D-LLM tasks section.
Problem Formulation
One can formulate a 3D-LLM as modeling a conditional distribution \(p_\theta(y \mid x, S)\), where \(S\) denotes the input 3D scene, \(x\) an optional text input, and \(y\) the task output.
The pipeline extracts 3D features \(f_{3D} = F(S)\), aligns them into the LLM space \(z = Align(f_{3D}, x)\), and generates outputs through the LLM as \(p_\theta(y \mid x, z)\).
Training typically uses a cross-entropy loss between the generated output and the ground truth, which can be expressed as:
\[\mathcal{L} = - \sum_{t} \log p_\theta(y_t \mid y_{<t}, x, S).\]3. 3D-LLM Tasks
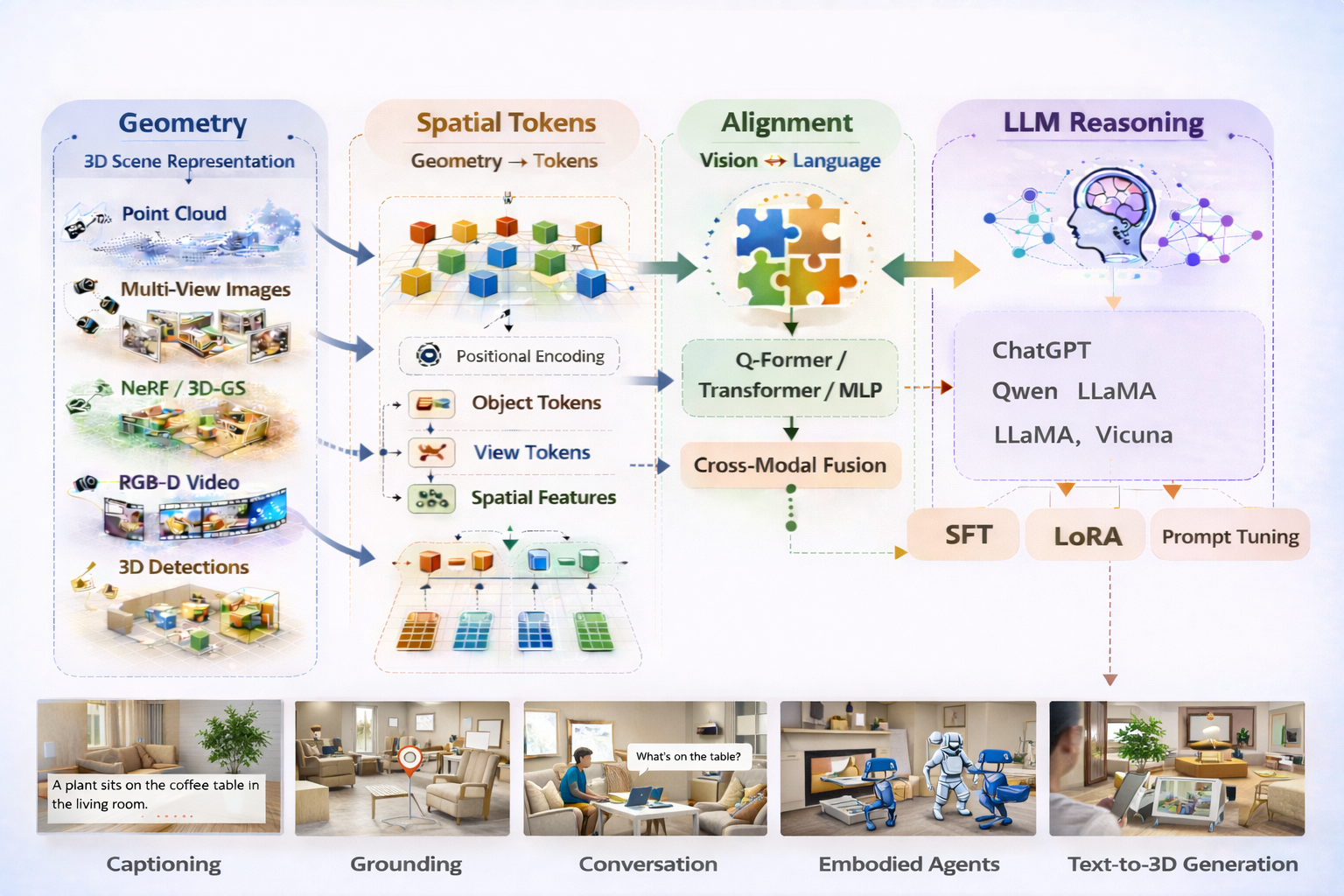
In this section, we present a structured taxonomy of 3D-LLM task formulations (adapted from the survey) to provide a comprehensive and guiding overview. The objective is to organize how language models interact with 3D representations by categorizing tasks based on their input–output modalities and functional objectives:
3D Captioning (3D → Text): Generating a natural language description for a given 3D scene or object. It can be categorized into (1) Object-Level Captioning, which describes the shape and semantics of individual 3D objects, and (2) Scene-Level Captioning, which focuses on the global layout, relationships, and overall context of a 3D scene. In addition, (3) Dense Captioning localizes object instances and associates each with a short descriptive caption.
3D Grounding (3D + Text → 3D Position): Given a 3D scene and a natural language query, the goal is to localize the referred object or region within the 3D space. This can be formulated as predicting a bounding box, a point cloud segment, or a coordinate corresponding to the textual description. Queries may refer to single objects, multiple objects, or spatial relationships between objects.
3D Conversation (3D + Text → Text): Questions are asked about a 3D scene, and the model generates natural language responses based on its visual and spatial understanding. This includes 3D Question Answering (3D-QA), Situated Question Answering (3D-SQA) from a specific viewpoint, and dialogue settings that require coherent multi-turn conversations about the 3D environment and its contents.
3D Embodied Agents (3D + Text → Action): Embodied agents must understand the 3D environment and execute actions accordingly. In this setting, 3D-LLMs generate action sequences conditioned on natural language instructions and scene understanding. This includes planning a sequence of steps to achieve a goal, navigation by interpreting the scene structure (e.g., obstacles and safe or optimal pathways) and generating movement commands, and manipulation to interact with objects within the environment.
Text-to-3D Generation (Text → 3D): Text-to-3D generation enables the creation of 3D content from textual descriptions. It includes (1) Object Generation, which produces 3D models of individual objects from text prompts, and (2) Scene Generation, which synthesizes complete 3D scenes that match a given textual description. This task is particularly challenging, as it requires understanding complex spatial relationships and generating coherent 3D structures aligned with the provided text. In addition, (3) 3D Editing involves modifying existing 3D assets based on textual instructions, such as changing the shape, appearance, or position of objects within a scene.
From the LLMs role perspective, the figure below, from the survey, illustrates the distribution of LLMs used across different 3D-LLM tasks, we use this as a reference to dive deeper into each role.
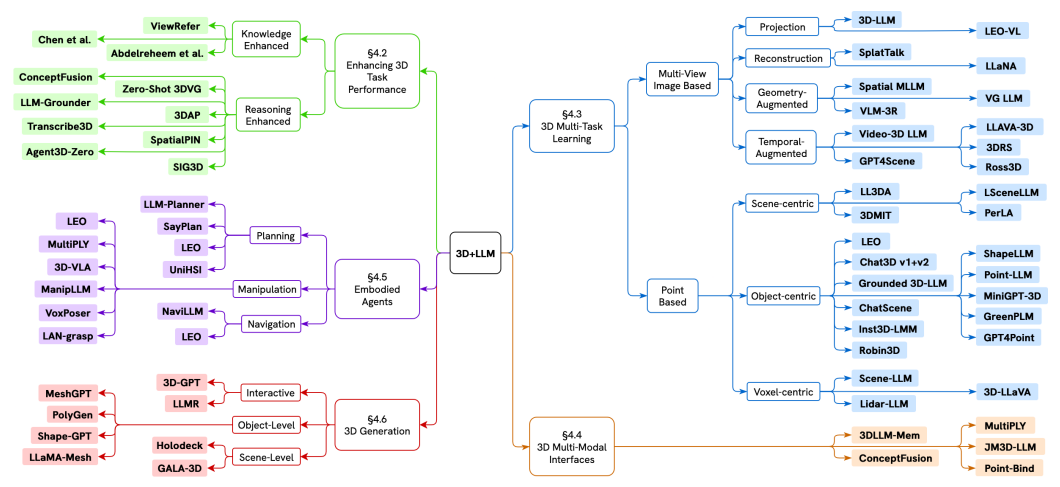
Figure: LLM roles across 3D tasks.
4. LLMs as an Enhancer
Well, LLMs have been used in two primary roles: (1) as a Knowledge Enhancer, and (2) as a Reasoning Agent. 3D tasks often require both semantic understanding and complex reasoning, and LLMs can be used to enhance either or both of these aspects.
Knowledge-Enhanced Approaches
These methods leverage LLMs to inject linguistic and commonsense knowledge into 3D task pipelines, enhancing semantic alignment. LLM enriches textual representations to reduce ambiguity and improve grounding performance.
For instance ViewRefer. take the challenge further and addresses the view discrepancy problem by incorporating view knowledge from both text and 3D modalities.
Assuming the coordinates are rotated into \(N\) different views, producing multi-view features \(F_v \in \mathbb{R}^{N \times K \times D}\), where \(N\) denotes the number of views, \(K\) the number of objects, and \(D\) the feature dimension.
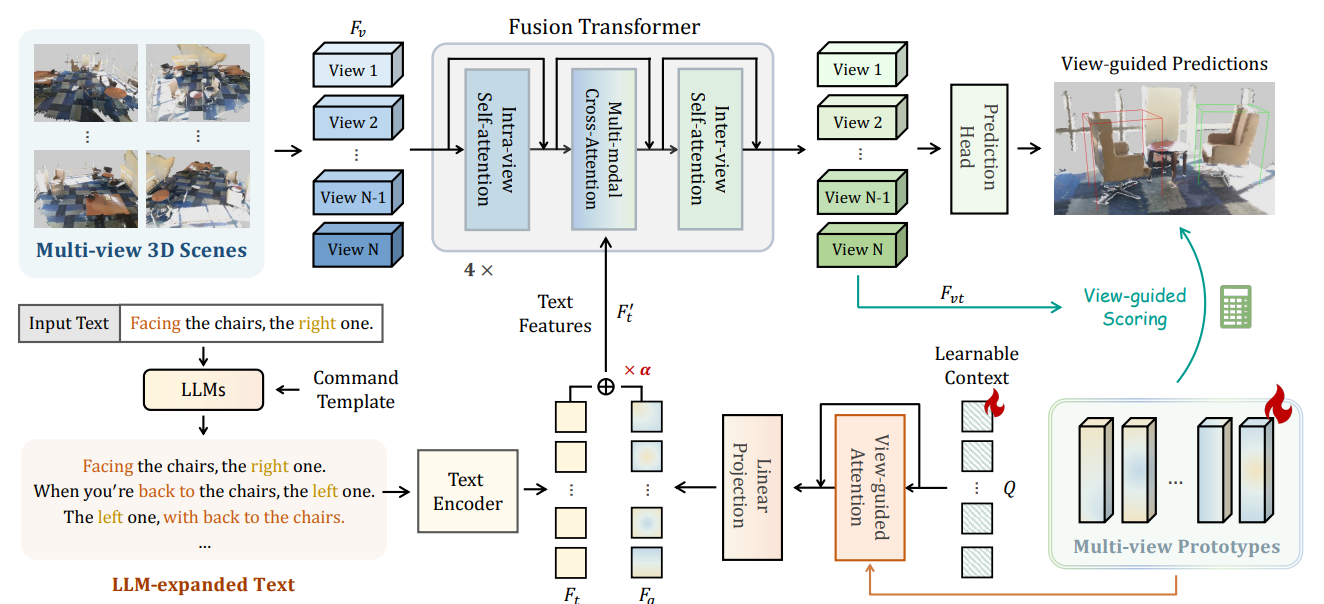
Figure: ViewRefer architecture.
On the text side, instead of relying on a single grounding sentence, the input description is fed into a LLM to generate \(M\) expanded grounding texts containing geometry-consistent view cues. These are encoded into features using BERT \(F_t \in \mathbb{R}^{M \times L \times D}\), where \(L\) is the maximum sequence length.
The multi-view 3D features and expanded text features are processed by a fusion transformer composed of cascaded blocks including intra-view self-attention, cross-modal attention, and inter-view self-attention. This enables interaction across both views and modalities, producing fused representations used for grounding prediction.
Additionally, ViewRefer introduces learnable multi-view prototypes that (1) provide view-guided contextual signals to the text branch and (2) re-weight the importance of different views during final scoring, as presented in the figure above.
The training objective combines cross-entropy losses for the reference grounding, the expanded text classification, and shape classification, weighted by hyperparameters \(\beta\) and \(\gamma\):
\[L = L_{ref} + \beta L_{text} + \gamma L_{3D}.\]Reasoning-Enhanced
LLMs are used to perform step-by-step reasoning over complex spatial queries, decomposing them into sub-tasks and execute them until the task is completed. LLM acts as an agent that plans, invokes tools, and reasons over feedback to make final decisions.
For instance, LLM-Grounder formulates 3D visual grounding as a multi-step reasoning problem, where the LLM decomposes a complex natural language query into semantic constituents and spatial relations.
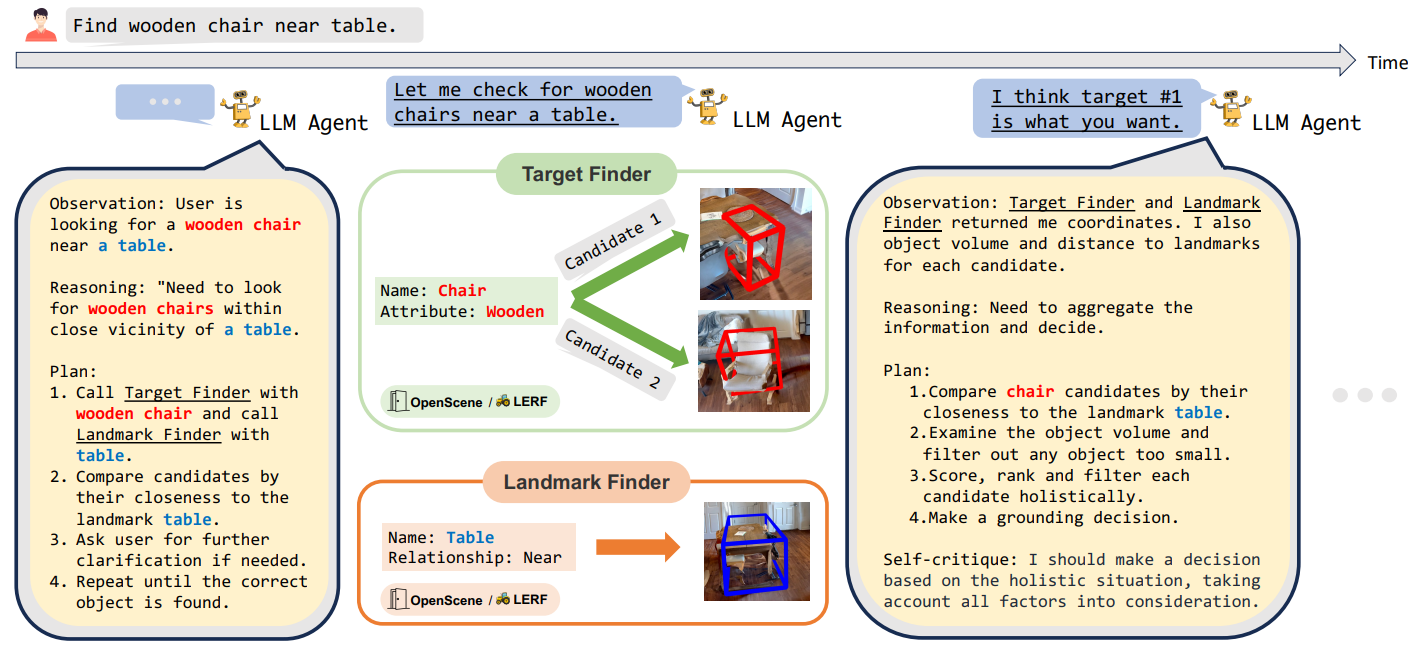
Figure: LLM-Grounder architecture.
As in the figure above, the LLM first performs:
- Planning: Breaking down the query into target objects and landmark objects with their spatial relationships.
- Tool Instruction Generation: Then LLM generates structured instructions for downstream grounding tools Target Finder to ground the primary object mentioned in the query, and Landmark Finder to ground secondary objects used for spatial reference.
Reasoning: The LLM then reasons over the tooling feedback, performing filtering based on constraints, the final grounding decision is made after evaluating both geometric consistency and language-derived constraints.
- Remark: No training is required for this process, as the LLM is used in a zero-shot manner, leveraging its inherent reasoning capabilities to perform the task without any parameter updates or fine-tuning or fusion module optimization.
5. LLMs for Multi-Tasking
LLMs can be used or fine-tuned to perform multiple 3D tasks within a unified framework. This can be achieved through either single-stage or multi-stage training strategies, using shared or task-specific alignment modules. Preparing appropriate data pairs for each task is essential, including captioning text, grounding coordinates, question-answer responses, planning steps, and manipulation action sequences.
LLMs can also assist in data annotation by generating task-specific samples through prompting or by merging multiple datasets with heterogeneous annotations. Hybrid approaches that combine human annotations with LLM-generated annotations can further improve scalability and data diversity.
In the following subsections, we explore different modeling strategies for multi-task 3D-LLMs, ranging from point-based representations to multi-view reconstruction-based methods, and finally to temporal-augmented video-based approaches. We begin with point-based representations, which directly lift visual features into 3D space before alignment with the language model.
Point-Based
For instance, point-based models suffer from the limited semantic richness due to their sparse nature, and the lack of explicit spatial structure. We explore the 3D-LLM, “3D-LLM: Injecting the 3D World into Large Language Models”, as a point-centric 3D and multi-tasking where the scene \(S\) contains rich feature representations supporting a diverse set of tasks under a unified generation framework for Dense captioning, QA, grounding, dialogue, and navigation-oriented reasoning formulated as conditional generation \(p_\theta(y \mid x, S)\).
The 3D-LLM extracts 3D points features from rendered multi-view images. Dense pixel-aligned features are extracted using pretrained image encoders, these 2D features are lifted back to 3D space \(F \in \mathbb{R}^{N \times D_v},\) where \(N\) is the number of 3D points and \(D_v\) the feature dimension.
Figure: 3D-LLM architecture.
These are directly injected into pretrained 2D VLM backbones (BLIP-2, Flamingo) using Perceiver-style or Q-Former alignment modules. The backbone VLM remains largely frozen, enabling data-efficient training. 3D-LLM introduces an explicit localization mechanism based on position embeddings derived from 3D coordinates are added to point features, and bounding boxes are discretized into voxel location tokens \(\langle x_{min}, y_{min}, z_{min}, x_{max}, y_{max}, z_{max} \rangle\), these tokens are incorporated into the LLM vocabulary.
For data generation, they design GPT-based prompting pipelines to automatically generate 3D-language samples across multiple tasks. Three strategies are employed:
- (1) boxes-demonstration-instruction prompting using axis-aligned bounding boxes of rooms and objects.
- (2) ChatCaptioner-based prompting where multi-view images are captioned and summarized into global 3D descriptions.
- (3) revision-based prompting to transform annotations across task formats. The dataset is constructed using 3D assets such as Objaverse, ScanNet, and HM3D.
Training is performed using cross-entropy over the collected multi-task dataset, where only alignment modules and localization-related parameters are optimized.
For reconstruction-based approaches, we first reconstruct the 3D scene using 3D Gaussian Splatting (3D-GS), which has become popular for its efficiency and high-fidelity rendering capabilities. The reconstructed representation is then aligned with the LLM embedding space for multi-task reasoning. Modern geometry-augmented methods avoid explicit projection or reconstruction pipelines. Instead, they rely on encoders such as VGGT that incorporate explicit geometric and semantic cues directly into the representation, without depending on rendered views or reconstructed surfaces.
For this matter, we explore two representative approaches, SplatTalk for reconstruction-based and Spatial-MLLM for geometry-augmented modeling.
3DGS (SplatTalk)
SplatTalk first reconstructs a geometry-aware 3D representation using 3D-GS, and then injects language-aligned features into this representation. The goal is to generate the corresponding language response for 3D visual question answering without relying on per-scene fine-tuning, expensive end-to-end training, or reverting to the 2D image space for multi-view fusion.
The core idea is to treat each 3D Gaussian as a spatial token enriched with semantic information. For each frame, high-dimensional visual tokens are extracted from a pretrained LLaVA-OV model after the multimodal projector for seamless alignment with the LLM space.
A generalizable autoencoder is trained to compress these features into a lower-dimensional representation \(D = 256\). These compressed features serve as pseudo ground-truth supervision for training the 3D Gaussian representation based on the FreeSplat framework, leveraging its multi-view consistency via Pixel-wise Triplet Fusion (PTF), and extending it with a language field.
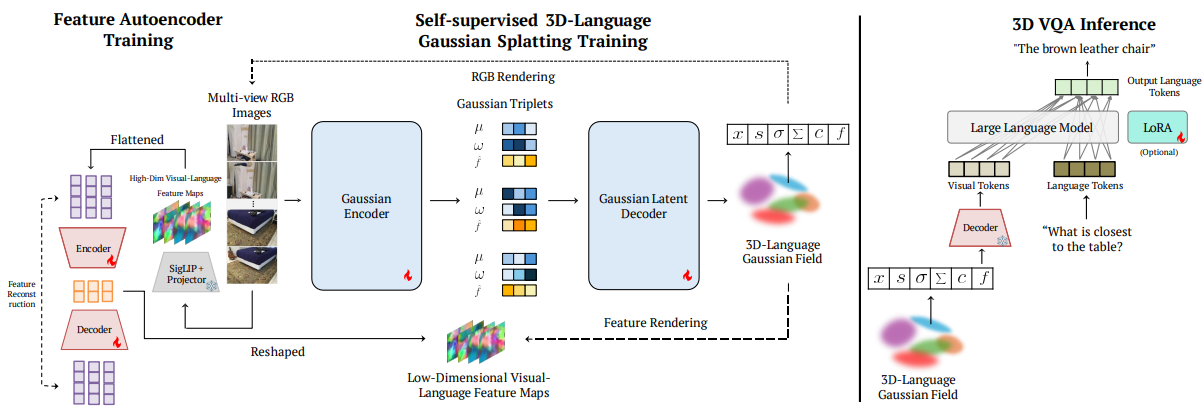
Figure: SplatTalk architecture.
During training, RGB and language features are jointly optimized. Each Gaussian learns a semantic feature vector \(f_i\), and through differentiable rendering, multi-view supervision aggregates 2D semantic information into 3D space. A CUDA rasterization pipeline is used to render RGB and semantic features simultaneously using shared Gaussian parameters.
The learned Gaussian feature can be interpreted as a weighted aggregation of semantic features across all viewpoints:
\[f_i^* = \frac{\sum_{t,x} R_i(t,x) F_t^{gt}(x)}{\sum_{t,x} R_i(t,x)},\]where \(R_i(t,x)\) denotes the contribution of Gaussian \(i\) to pixel \(x\) at view \(t\).
At 3D-VQA inference, semantic features are extracted at the mean position of each Gaussian and treated as 3D tokens. Unlike 2D patch tokens arranged in a grid, these 3D tokens form an unordered spatial set, where geometric relationships are implicitly captured by the learned features and their 3D coordinates.
Because complex scenes may contain more Gaussians than the LLM’s token capacity, SplatTalk introduces Entropy-Adaptive Gaussian Sampling. Only the top-\(k\) Gaussians with the highest feature entropy are selected, ensuring that the most informative spatial-semantic tokens are provided to the LLM.
These selected 3D tokens are then directly fed into the pretrained LLM, together with the language prompt, enabling zero-shot 3D VQA. Optional fine-tuning can be performed using LoRA adapters applied to the LLM, avoiding expensive end-to-end retraining.
VGGT-Based (Spatial-MLLM)
Spatial-MLLM use 3D foundation models as bottleneck modules to enhance spatial reasoning without relying on explicit 3D reconstruction, depth maps, or point clouds, enabling improved reasoning over geometric relationships, distances, and layout.
Spatial-MLLM injects 3D structural priors extracted from a feed-forward visual geometry foundation model VGGT for instance, while still operating purely on 2D video inputs as multi-view geometry-aware features.
Given a video sequence \(V = \{f_i\}_{i=1}^N\), Spatial-MLLM uses a dual-encoder architecture, a semantic encoder \(E_{2D}\), initialized from Qwen2.5-VL, extracting patch-level semantic features and a spatial encoder \(E_{Spatial}\), initialized from VGGT, extracting dense 3D structure-aware features, Formally \(e_{2D} = E_{2D}(V), \quad e_{3D} = E_{Spatial}(V)\).
The 2D branch captures semantic content, while the VGGT-based spatial encoder learns from pixel–point correspondences, encoding strong geometric priors directly from 2D inputs.
A lightweight connector (2 MLPs) aligns and fuses the two feature streams, after a simple rearrangement to match the spatial and temporal dimensions, as:
\[e = \text{MLP}_{2D}(e_{2D}) + \text{MLP}_{3D}(e_{3D}),\]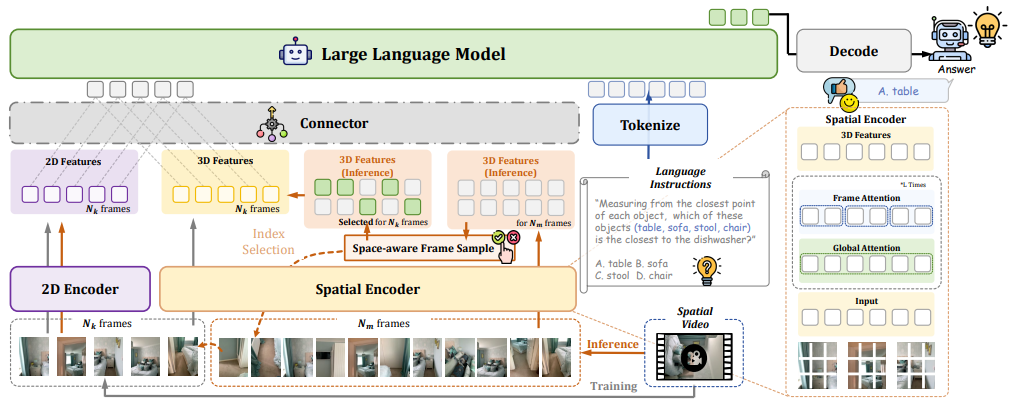
Figure: Spatial-MLLM architecture.
producing unified visual tokens that are fed into the LLM backbone.
The second key innovation is space-aware frame sampling. Since video MLLMs can only process a limited number of frames (N=16), a uniform sampling may miss spatially informative viewpoints.
Spatial-MLLM instead leverages VGGT’s predicted camera parameters and depth maps to compute Voxel coverage for candidate frames. Frame selection is formulated as a maximum coverage problem: select \(N_k\) frames that maximize the union of covered voxels.
This ensures that selected frames collectively capture the most spatially informative parts of the scene, yet it might be seen as drawback for larger scenes with many occlusions, where a small number of frames may not capture the full spatial context.
In terms of data and training, the authors construct Spatial-MLLM-120k, a large-scale visual spatial QA dataset derived from ScanNet scenes. It includes object counting, size estimation, distance measurement, relative direction, room size, and spatial ordering taks …
Training proceeds in two stages:
Supervised Fine-Tuning (SFT): The dual-encoder connector and LLM backbone are trained with cross-entropy loss \(\mathcal{L}_{CE} = - \sum_i \log P(o^{(i)} \mid o^{(1:i-1)}, q, \{f_j\})\) Both \(E_{2D}\) and \(E_{Spatial}\) remain frozen.
Reinforcement Learning: To improve long chain-of-thought spatial reasoning, Group Relative Policy Optimization (GRPO) is applied for better matching structured spatial reasoning rewards while controlling KL divergence from the reference policy.
In summary, Spatial-MLLM demonstrates that geometry-aware encoders can substantially improve spatial intelligence in MLLMs without requiring explicit 3D inputs as in SplatTalk, depth maps, or point clouds.
Video-3D LLM
Video-3D LLM formulates 3D scene understanding and reasoning as a position-aware video modeling problem, avoiding a 3D reconstruction step, No scene graph or 3D map.
The model takes as input RGB-D video together with camera intrinsics and extrinsics. For each frame \(f_k\) with depth map \(d_k\), global 3D coordinates are computed via back-projection \(c_k(i,j) = T_k \Big( d_k(i,j)\, K^{-1} [\, j,\; i,\; 1 \,]^\top \Big)\) producing dense coordinate maps \(c_k \in \mathbb{R}^{H \times W \times 3}\). These coordinates serves as spatial signals injected directly into video tokens.
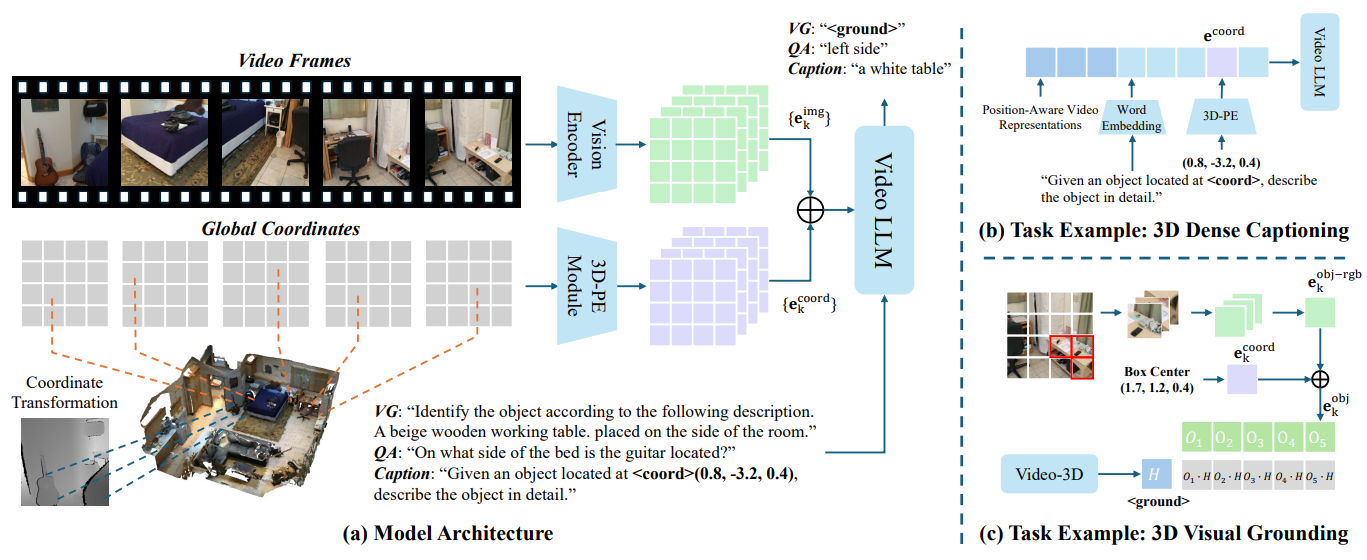
Three major key contributions are proposed:
- Frame selection and Maximum Coverage Optimization: Similar to Spatial-MLLM, Video-3D LLM also faces the challenge of selecting a limited number of frames, a frame selection process is formulated as a maximum coverage optimization problem.
With a set of frames \(F\) and a set of discretized voxels \(V\), each frame covers a subset of voxels \(V_k \subseteq V\), the objective is to maximize the total covered voxels by selecting a subset of frames using a greedy algorithm.
Position-Aware Representation: Each selected RGB frame is encoded using a Vision Transformer (ViT), which divides the image into patches and produces patch-level visual embeddings \(\mathbf{e}_k^{img}\) with dimention \(d\). Also, the 3D coordinates are pooled for each path to align with the patch tokens, and encoded using sinusoidal 3D positional encoding, along the \(x,y,z\) axes, to produce coordinate embeddings \(\mathbf{e}_k^{coord}\), which are simply added to the visual embeddings to create final visual tokens \(\mathbf{e}_k^{vis} = \mathbf{e}_k^{img} + \mathbf{e}_k^{coord}.\)
Unified Multi-Tasking: The same position-aware video tokens are used across multiple tasks, including 3D QA, dense captioning, and visual grounding. Each batch contains data fro specific task. Standard cross-entropy loss is applied for QA and dense captioning tasks, for 3D visual grounding, an InfoNCE loss is used to align proposal features with the hidden state.
For dense captioning, the 3D center of an object’s bounding box is encoded via the same 3D positional encoding mechanism and added to a special \(\langle coord \rangle\) token to condition object-centric descriptions.
The formulation of grounding transforms it into similarity-based selection, classification rather than geometric regression, improving stability within an LLM-based architecture.
Key Takeaways
Most 3D-LLM systems follow a two-step process: first represent the 3D geometry, then connect it to a pretrained language model using small alignment modules.
The main difficulty is fitting rich 3D spatial information into a limited number of tokens without losing important details about geometry and relationships. Different approaches balance this trade-off in various ways.
Future progress depends on better connecting continuous 3D space with discrete language tokens so models can reason about the physical world more effectively.
Summary of 3D-LLM Design Patterns
| Method | Year | Geometry | Vision Model | LLM Base | Alignment Module | Training (3D / LLM) |
|---|---|---|---|---|---|---|
| 3D-LLM | 2023 | Point Cloud | Mask2Former / SAM | OPT / Flan-T5 | Q-Former | Frozen / Frozen (train alignment) |
| ViewRefer | 2023 | Multi-View | Multi-View Transformer | GPT-3 | Transformer | Fine-tuned / Prompt-based |
| LLM-Grounder | 2023 | Point Cloud / NeRF | LERF | GPT-3.5 / 4 | N/A | Frozen / Prompt-only (zero-shot) |
| SplatTalk | 2025 | 3D-GS | SigLIP | Qwen2 | MLP | Fine-tuned (3D field) / LoRA optional |
| Spatial-MLLM | 2025 | Multi-View Images | VGGT | Qwen2.5-VL | MLP | Frozen encoders / SFT + RL |
| Video-3D LLM | 2024 | Multi-View RGB-D | SigLIP | Qwen2.5-VL | Transformer + MLP | Fine-tuned (video encoder) / Frozen LLM |
Insights Across Benchmarks
Across benchmarks such as ScanRefer, ScanQA, and SQA3D, a consistent trend emerges: models that explicitly incorporate spatial priors,through geometry-aware encoders or position-aware video modeling, tend to perform better on tasks requiring relational and layout reasoning.
These results suggest that performance gains stem less from larger LLM capacity and more from how effectively geometric structure is encoded and aligned.
References
- Guo et al., 2023: ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding with GPT and Prototype Guidance.
- Yang et al., 2023: LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent.
- Hong et al., 2023: 3D-LLM: Injecting the 3D World into Large Language Models.
- SplatTalk, 2025: SplatTalk: Language-Embedded 3D Gaussian Splatting for 3D Visual Question Answering.
- Wu et al., 2025: Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence.
- Zheng et al., 2024: Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding.
- Ma et al., 2024: When LLMs Step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models.
- Awesome-LLM-3D: Curated list of 3D + LLM papers and related foundation models.